
TotalAgility Third-Party Extraction Framework
TotalAgility Third-Party Extraction Framework Overview
Features
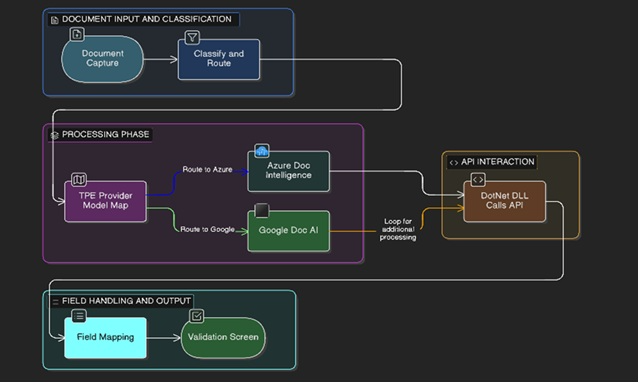
Multi-provider extraction framework Connects Tungsten TotalAgility with third-party AI extraction providers — Microsoft Azure Document Intelligence and Google Cloud Document AI — to extract fields, line items, and bounding box coordinates from documents.
Unified DLL entry point A single Extract method handles provider routing, document retrieval via the TotalAgility SDK, model resolution, and API communication — no need to call provider-specific classes directly from TotalAgility processes.
Central JSON-based routing configuration Document types are mapped to provider-specific model or processor IDs via a single TPE-MODEL-MAP server variable. Adding a new document type requires only a configuration change — no code modifications needed.
Field-level bounding box highlighting Extracted field values are mapped with precise bounding box coordinates, enabling field highlighting on the document image in TotalAgility's validation screen for Driving License and Receipt document types.
Line item and table extraction Supports multi-row table extraction for Receipts and Invoices, mapping individual item fields (Description, Quantity, Price, Amount, ProductCode) to extraction group table columns.
Cloud-environment compatible The Google Document AI integration includes a pure managed RSA-SHA256 signing implementation using BigInteger.ModPow, bypassing Windows Crypto API and CAS restrictions in Tungsten Cloud environments.
Reusable subprocess architecture Common operations — field extraction, position calculation, entity matching — are built as reusable, document-type-agnostic subprocesses shared across all document types.
Fully extensible framework The same framework can be extended to support additional document types (by updating configuration and cloning processes) or entirely new extraction providers (by adding a new DLL class and TotalAgility processes).
Benefits
Enables TotalAgility to leverage specialized third-party AI extraction services from Microsoft Azure Document Intelligence and Google Cloud Document AI, reducing the need for custom integration development.
Provides a multi-provider framework that allows organizations to route different document types to different AI providers based on extraction quality, cost, or preference.
Delivers extracted field values with precise bounding box coordinates, enabling field-level highlighting in TotalAgility's validation screen for faster and more accurate document review.
Supports line item and table extraction for complex document types like Invoices and Receipts, mapping structured data directly into TotalAgility extraction groups.
Offers a fully extensible architecture — new document types can be added with configuration changes only, and new extraction providers can be added by following documented patterns in the Blueprint guide.
Works in both on-premise and Tungsten Cloud environments, with a pure managed RSA implementation that bypasses CAS restrictions for Google OAuth2 authentication.
Technical Details
Inputs
TPE-PROVIDER – Determines the active extraction provider. Set to Azure for Microsoft Azure Document Intelligence or Google for Google Cloud Document AI.
TPE-MODEL-MAP – A JSON string that maps document type names to provider-specific model IDs (Azure) or processor IDs (Google). This is the central routing configuration for the framework.
TPE-TimeoutSeconds – Maximum time in seconds to wait for a response from the third-party AI provider before timing out (e.g., 60).
TPE-AZURE-ENDPOINT – Azure Document Intelligence endpoint URL, obtained from the Azure portal (e.g., https://your-resource.cognitiveservices.azure.com/).
TPE-AZURE-API-KEY – Azure Document Intelligence API key used for authenticating REST requests.
TPE-AZURE-API-VERSION – Azure Document Intelligence API version (e.g., 2023-07-31).
TPE-GOOGLE-LOCATION – Google Cloud Document AI processor region (e.g., us or eu).
TPE-GOOGLE-SA-JSON – Full content of the Google Cloud service account JSON key file, containing credentials required for OAuth2/JWT authentication.
TotalAgility SDK URL – URL for connecting to the TotalAgility SDK service, used to retrieve document bytes at runtime.
Session ID – Active TotalAgility session identifier.
Document ID – TotalAgility document instance ID used to identify and retrieve the document for extraction.
Document Type – The classified document type name (e.g., DriverLicense, Receipt, Invoice), used to resolve the correct model/processor from TPE-MODEL-MAP.
Outputs
The Third-Party Extraction Framework produces one or more of the following outputs after execution within a TotalAgility workflow:
Raw JSON Response – The complete JSON response string returned by the third-party extraction provider (Azure Document Intelligence or Google Document AI), containing all extracted fields, confidence scores, and bounding box coordinates.
Extracted Field Values – Individual field values (e.g., MerchantName, InvoiceTotal, FirstName) mapped to the corresponding TotalAgility extraction group fields for the classified document type.
Bounding Box Coordinates – Field-level position data (Top, Left, Width, Height) calculated from provider polygon coordinates and written to extraction group field properties, enabling field highlighting on the document image in the validation screen.
Line Items / Table Data – For document types with tabular data (Receipts, Invoices), individual item rows with mapped column values (Description, Quantity, UnitPrice, Amount, ProductCode) inserted into the extraction group table.
Confidence Scores – Provider-assigned confidence values for each extracted field, available in the deserialized data model for use in validation rules or low-confidence flagging.
Success or Error Response – If the provider call fails, an exception is returned to the TotalAgility process with details including HTTP status code, error message, and provider-specific error body for troubleshooting.
Geographic Availability
Additional Information
The Third-Party Extraction Framework is designed to simplify and accelerate the integration of external AI-powered document extraction providers with Tungsten TotalAgility. It provides a ready-to-use, extensible solution that enables TotalAgility workflows to route documents to Microsoft Azure Document Intelligence or Google Cloud Document AI, extract field values with bounding box coordinates, and map results directly into TotalAgility extraction groups for validation — without requiring custom development.
All framework configuration, including provider selection, model/processor routing, authentication credentials, and API settings, is managed centrally using TotalAgility Server Variables and a single JSON routing map (TPE-MODEL-MAP). Document types are mapped to provider-specific AI models at the configuration level, meaning new document types can be added without any code changes.
The solution includes a TotalAgility package, complete C# source code, and a comprehensive Blueprint & Implementation Guide covering architecture, setup, process reference, troubleshooting, and step-by-step How-To guides for adding new document types or entirely new extraction providers.
This framework is ideal for organizations looking to complement TotalAgility's native extraction capabilities with specialized third-party AI services, support multi-provider strategies, or build a reusable extraction architecture that can be extended across document types and providers. It works in both on-premise and Tungsten Cloud environments.



